Create API
AI Video Generator API
Combine AI voices, images, and your existing media to produce thousands of videos programmatically. One AI video generator API for your entire pipeline. Developer sandbox included.
Start for Free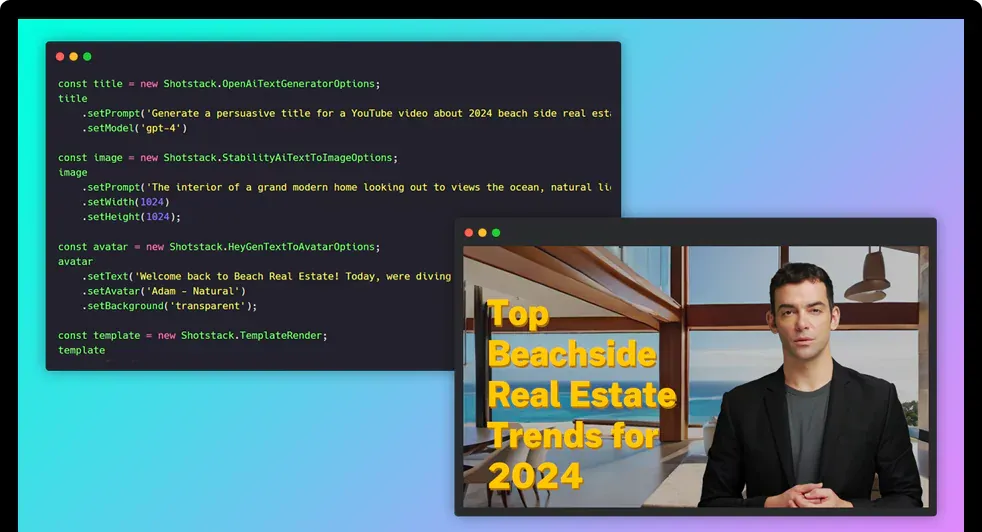
Combine AI voices, images, and your existing media to produce thousands of videos programmatically. One AI video generator API for your entire pipeline. Developer sandbox included.
Start for FreeOver 20,000 Businesses & Developers from 119 Countries Trust Shotstack
Your business needs videos with AI-generated assets at scale. You could use AI codegen and stitch a pipeline together in an afternoon. But do you really want to spend time building and maintaining video infrastructure?
No other platform brings everything together.
Most teams patch together separate APIs for text-to-speech, text-to-image, avatars, and video editing. The result is a tangled mess of code, SDKs, and API keys that is difficult to maintain and manage.
Shotstack unifies this flow into a single, model-agnostic video generation API that handles rendering and delivery, turning raw assets into videos — without rebuilding your entire stack.
Creating one video is easy; creating 10,000 is an engineering problem.
We've already solved the technical challenges of programmatic video production for you. Our API transforms JSON templates into finished videos with enterprise-grade infrastructure:
Most video editors can’t handle this kind of workflow. Shotstack is built for them.
It would have taken a lot of research on what technologies we needed to leverage to achieve the desired outcome. This would have taken at least two months of engineering time for a simple use case, and up to 6 months if the scope widened.
Create fully edited videos with a single call. One AI video generator with an API that brings everything together. Connect your data and AI assets, automate the editing, and ship finished videos.
Use Shotstack's text-to-image service to generate images from a simple text prompt. Access the latest models and easily switch between them, ensuring you get the best results.

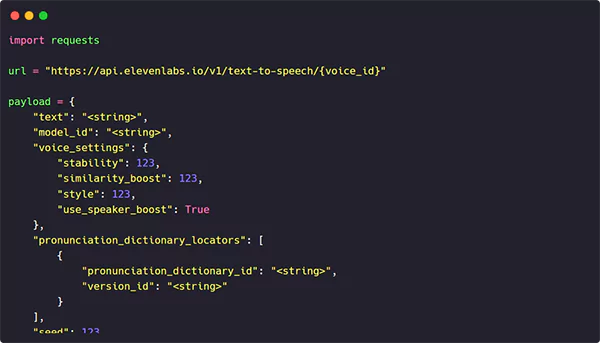
Generate voice-overs for your videos. Combine voices, accents, and translations into a single, beautifully designed video via the unified AI video generation api.

Bring your images to life in the form of a video. Provide the URL of an image, and AI will turn it into a short video to use in your edits. Perfect for product catalogs, listings, and highlight reels.
Ingest clips from an AI avatar provider, then add lower thirds, graphics, subtitles, and music to deliver polished presenter videos.

Create powerful video workflows and applications using AI and programmatic video editing tools.
Render thousands of videos in minutes with battle-tested, cloud-based video editing infrastructure.
Unlimited developer sandbox
No credit card required